
I have to confess that the core message of this post is not really a fresh saying. But if I was given a chance to deliver one dataviz advise to every (ha-ha-ha) listening mind, I’d choose this: forget multi-category bar plots and use dotplots instead.
I was converted several years ago after reading this brilliant post. Around the same time, as I figured out later, demographer Griffith Feeney wrote a similar post. From fresher examples, there are chapters discussing dotplot visualizations in Claus Wilke’s book and Kieran Healy’s book. So, what are dotplots and what’s so special about them?
Basically, dotplots are the same regular barplots rotated 90 degrees and optimized on “ink usage”, i.e. dots represent values along the continuous horizontal axis. This leaves the vertical axis for the categorical variable allowing to write out long labels for the categories as normal horizontally aligned text (nobody likes to read that awful 45 degrees labels). The use of dots instead of bars allows to represent several comparable values for each category.
Here is a sample of some ugly plots that I found in the recent papers in my personal library of papers.
It was not difficult to compose such a selection as these plots are, unfortunately, super popular. I think, the guy to blame here is (surprise-surprise) Excel. I’m failing to understand how such a basic plot type can be missed out.
Just to be clear, I’m guilty too. Before the happy rstats-ggplot switch, I’ve been producing the same Excel plots. Here is an example from my 2014 working paper on internal youth migration in the central regions of Russia.
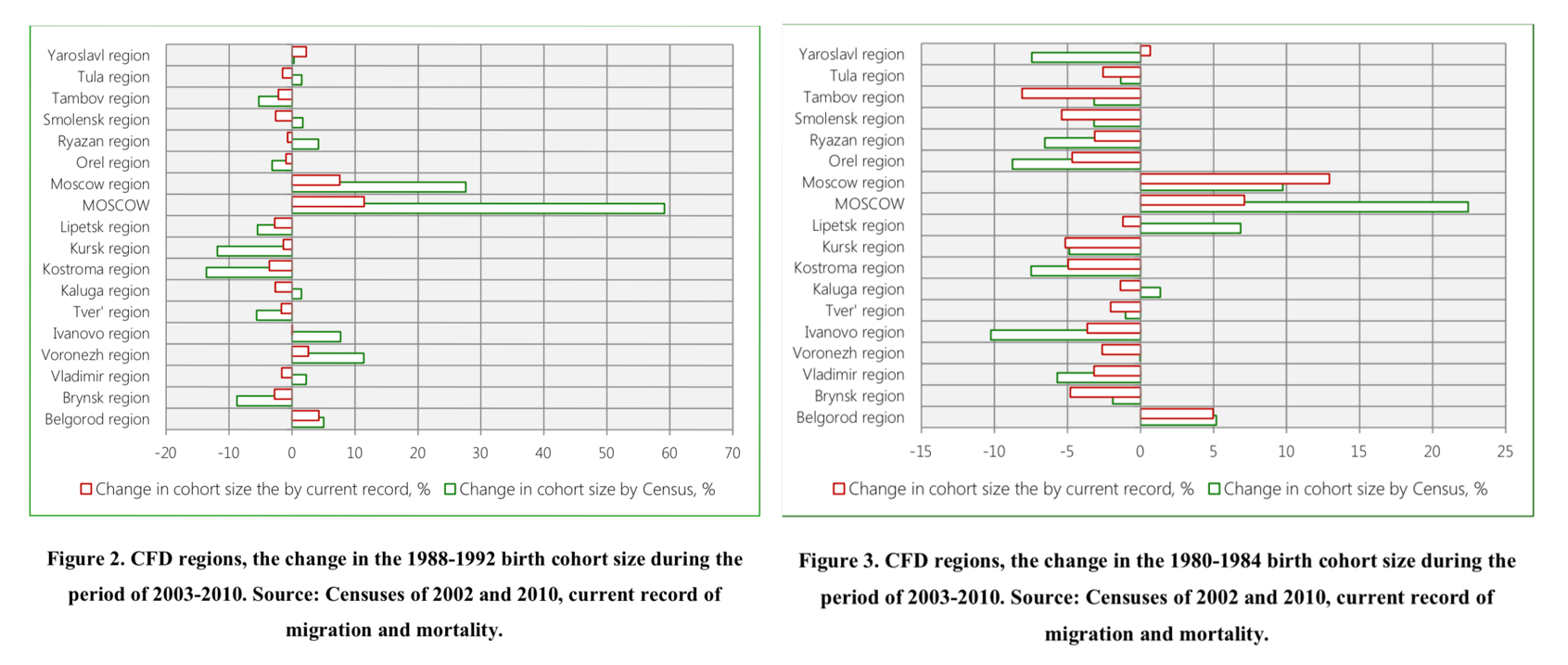
These two figures became one in the final paper recently published in GeoJournal. I think it’s a nice example how information dense, pretty looking (very subjective here), and easy to read a dotplot can be.
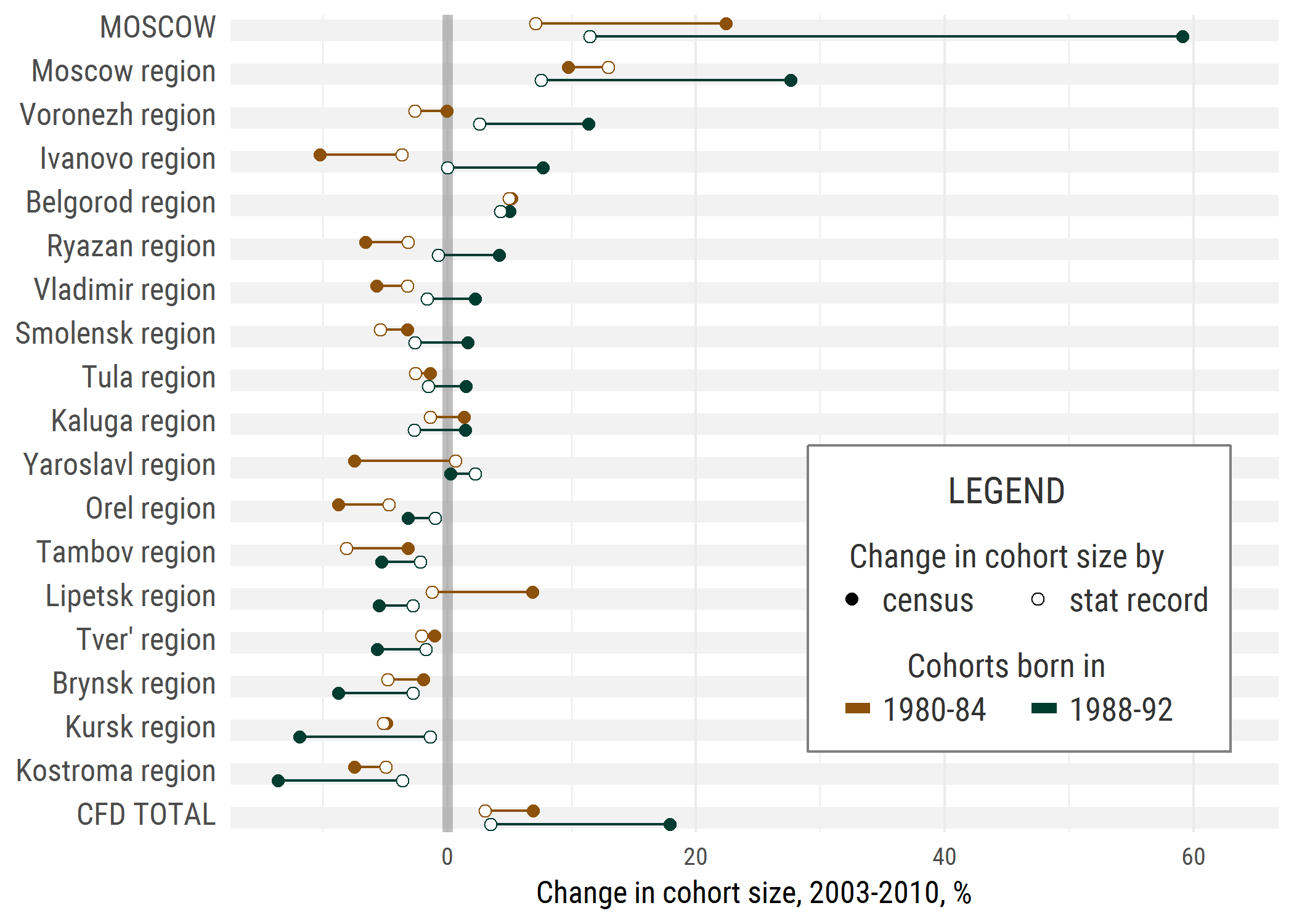
The figure shows discrepancy in migration estimates based on statistical record and census indirect estimates.
The code to replicate this figure is in this gist. A couple of coding solutions might be interesting here. First, the trick to offset vertically the dots for the two cohorts. Yet I realise that the way I implemented it is a bit clumsy; if you know a more elegant solution please let me know. Also, I believe in some cases composing the legend manually pays off, especially when we are dealing with two-dimensional legend. If the plot has some empty area it’s always a good idea to move the legend in the plotting area thus cutting away the margins.